测试人员如何用好RAG
2025-06-11
大语言模型(LLM)已成为越来越多软件测试人员的得力助手。从生成测试用例到生成Page Object模型,我们常常希望:能不能一口气把所有上下文喂给模型,让它“一次性”给出最完美的答案?
但事实并不理想。就像你不能把一本完整的操作手册一股脑塞给一个刚入职的实习生,指望他第二天就能独当一面一样,大语言模型也有“接收极限”——这就是所谓的上下文窗口限制。我们不能简单粗暴地把所有代码、文档全都塞进一个提示词(prompt),然后期待模型表现得比人类还聪明。
RAG一般工作流程图
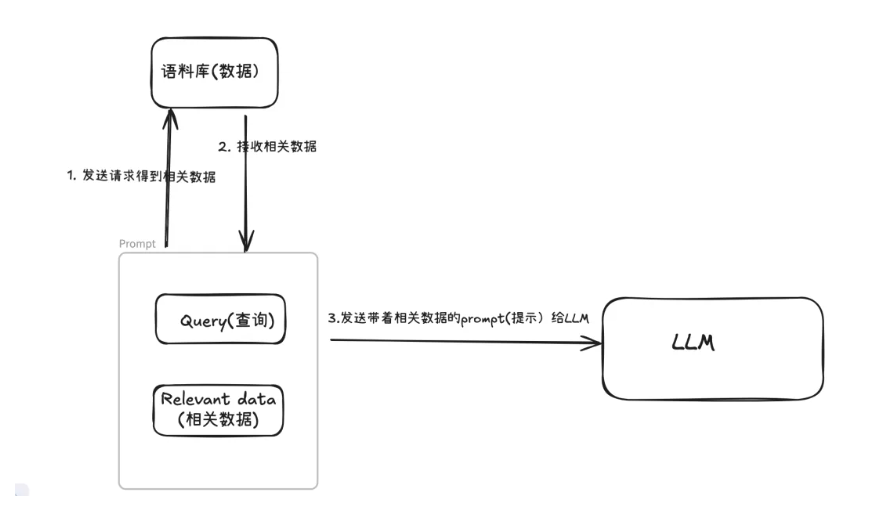
以上是对RAG工作流程的一个简单介绍,如下文章内容将对此详细展开。
不要“堆料”,要“讲重点”
与其用蛮力“灌输”上下文,不如巧妙地“提炼”信息,让模型恰到好处地理解我们要做什么。换句话说,有效的提示词不是“大而全”,而是“精而准”。
比如,你想让模型为某个页面生成自动化测试用的 Page Object。你可以选择把整个前端代码库扔进去(然后模型一脸茫然),也可以只提供该页面的HTML结构、关键的交互点和相关组件信息。后者不但效率高,还能让回答更贴合实际。
听起来很合理,对吧?但问题来了:如何判断哪些信息是“必须的”?哪些是“无关紧要的”?手动去筛选这些内容,既耗时又枯燥——这正是“RAG”(检索增强生成)闪亮登场的舞台。
什么是RAG?它是你的提示词“情报官”
RAG,全称是Retrieval-Augmented Generation(检索增强生成)。你可以把它理解为提示词的“智能助手”或“情报官”——它的职责是:在你提出问题的同时,自动从预先准备好的知识库中,找出最相关的上下文信息,打包好,再一并送给大语言模型。
用一个比喻来说,这就像你向AI提出“请帮我生成一个预订列表页的Page Object”的请求,RAG就会默默地从“页面资料库”中查找,发现“哦,这个HTML文档里刚好是预订列表页的结构”,然后自动把这份资料附加到提示词中提交给模型。AI收到的,就是一个经过精心包装的、上下文充分的请求,自然可以做出更准确、更贴合的回应。
RAG并不只是处理HTML,它同样适用于代码片段、接口文档、测试报告、数据库字段,甚至探索性测试笔记、自动化测试脚本等内容。只要数据结构清晰、可检索,它就能“打包上阵”。
为什么RAG对测试人员特别重要?
测试人员面对的问题往往都不是“标准答案”,而是开放性、上下文相关的。比如:
某个按钮到底有没有被正确测试过?
当前业务流程中,风险最高的逻辑点是什么?
有没有遗漏某些边界条件?
自动化代码和实际业务逻辑是否匹配?
这些问题往往需要结合具体代码、历史Bug记录、测试脚本和需求说明才能回答清楚。这种需要“上下文判断”的任务,恰恰是RAG最擅长的场景。
比如你正在写一个自动化测试的用例生成提示词,但手上只有一堆零散的代码。此时RAG可以帮助你:
自动识别代码中对应的页面结构;
检索相关的测试用例模板或历史测试日志;
提取有价值的参数或行为逻辑;
构建一个结构化且高质量的prompt。
最终效果是:你不再是“盲人摸象”地写prompt,而是有策略、有数据支持地构建高质量请求。
测试人员应该如何掌握RAG技能?
1. 学会构建“知识语料库”
RAG之所以有效,是因为它有一个好用的信息库(corpus)。这就要求我们测试人员具备一定的数据整理能力:
把测试用例、Bug记录、测试脚本、接口文档等归档整理;
使用统一格式(如Markdown、JSON、HTML)存储;
为文档打上有意义的标签,便于后续检索。
你的数据质量,决定了RAG的智能程度。
2. 理解“提示意图”与“信息配对”
在构建prompt时,你要清楚自己到底在问什么,然后思考这个问题最需要哪类信息:
是前端结构?(那就找HTML)
是接口文档?(那就找OpenAPI描述)
是历史测试用例?(那就找Test Case库)
这个过程有点像“搭配衣服”,不是越多越好,而是越配越出彩。
3. 掌握一些技术工具或框架
目前很多RAG工具和框架(如LangChain、LlamaIndex)都支持代码和测试相关场景。如果你具备Python基础,可以考虑:
使用LangChain + FAISS 实现简单的测试知识库检索;
搭建一个小型本地文档嵌入引擎;
利用Playwright、Postman等测试工具生成的文档作为语料源。
不必一开始就追求复杂系统,从自己的项目资料开始实践即可。
写在最后
对测试人员来说,RAG并不是一个“遥不可及的高端技术”,而是一个实用性极强、门槛相对较低的工具框架。它可以帮你省掉大量手动整理提示词的工作量,也能提升大模型在测试任务中的准确性与可解释性。
未来,RAG甚至可以嵌入到测试平台、测试管理工具中,成为一种“类智能测试助手”的基础能力。
在AI时代,测试人员不再只是“执行者”,而是信息整合者、策略设计师、智能系统的指挥官。而RAG,就是你通往这一角色转变的关键一步。
如果你也希望掌握RAG并应用在自己的测试实践中,不妨从今天开始,整理你的测试数据、思考你的提示目标,并尝试构建第一个“可检索、可生成”的提示任务吧。
RAG不会替代你,但它一定会增强你。
文章出处:https://mp.weixin.qq.com/s/lF8zZmmEkRXhCUyoWrRE0w 如有侵权,联系删除!